Skimming Expert Info Dump#
- Author:
Cameron Harris
If you have come here I can only assume you too wonder how the skimming in VIBE actually works. Well this section aims to answer the questions I had as I was developing the tools to add to this amazing validation framework.
The inception of the idea#
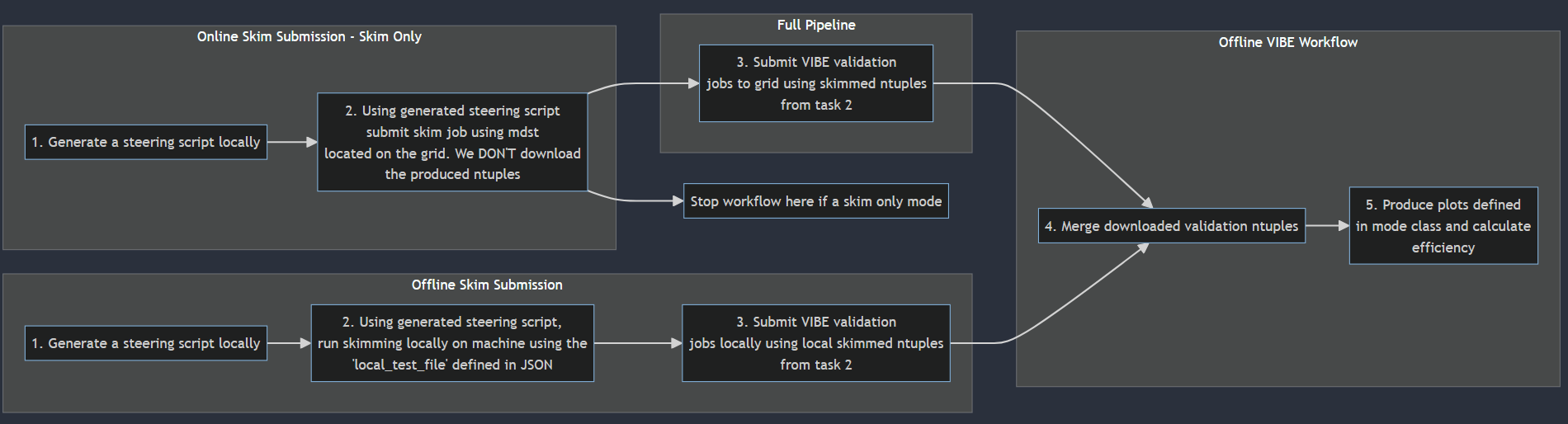
The idea for this workflow came from my fellow PhDs at the University of Adelaide. We have a history of being the WG1 skim liaison’s and as such have each had a go at creating out own framework for handling validating skims for WG1. However, I am the first to attempt this using b2luigi to orchestrate the skimming-validation workflow. The reason I’m the first? This will become apparent in the next section. The workflow was scribbled on a scrap piece of paper one afternoon when my liaison predecessor Shanette and I were discussing what we would want in a skim-validation workflow. The formalised version is right there at the top of this section. We wanted:
To be able to submit skims to the grid using b2luigi (duh)
Be able to toggle between just submitting skims and submitting the full skim-validation workflow to the grid
Be able to replicate 2. offline on a local machine
Create a suit of plots and statistical metrics
Generate a templated, dated PDF from the outputs of the validation
Frank Meier, my qualification task supervior (yes my QT task) brought VIBE to my attention when I pitched my skim-validation idea to him. VIBE was the perfect skeleton to work off as Patrick had created a wonderful piece of software that was easily extendable. What I detail in the rest of this document is what I learnt along the way, what challenges presented themselves and the knowledge I gained. I feel it would be sad to not detail what I have learnt so that others may learn from this too.
Note
Now if you have used skimming in VIBE you may know that 5. and 6. are not yet in VIBE but no need to worry, they will be coming.
What was stopping skims being added to VIBE?#
I feel the best way to discuss the hurdles to adding skimming to VIBE is to start with the first major problem that had to be solved.
b2luigi gbasf2 submission workflow#
This issue was generally known prior to be me starting this endeavour. The workflow that b2luigi takes to submit a gbasf2 job is as follows:

The key thing here is the second step, where b2luigi attempts to pickle the basf2 path that we returned, in the case of VIBE from our create_basf2_path method. Every skim in Belle II is a child class of BaseSkim, which when called like so:
#-- Code that generates a skim instance object for a given skim mode along with a basf2 path
skim(path)
#-- More code after calling the skim instance
will add modules to the basf2 path. One of these modules is the initialiseSkimFlag module which, as you might guess, is a python module. This is a required module for EVERY skim in Belle II and so b2luigi couldn’t submit any jobs that contained skimming. Another issue comes from conditional basf2 paths, the BaseSkim handles the situation where multiple throw-away paths need to be used to handle different particles lists etc. However, this conditional path situation is not picklable either. Hence, we have the first major issue that needed to be solved.
The issue is certainly obvious, we can’t pickle python modules or conditional paths. Both of these things are present in every skim in Belle II. So how do we find a solution? One way would be to rewrite initialiseSkimFlag as a C++ module but I think that could be the least favourable option as I don’t know C++. But I do know python, well. So that leads me to modifying how b2luigi (a fully python package) submits jobs. I can see why pickling the path and using a templated standardised steering script is favourable, you guarantee all jobs submitted have the same steering file and have a known basf2 path module set at run time.
However, within VIBE I intend to generate every skim steering script using the commandline tool b2skim-generate, which uses a templated standardised base steering script that handles both singular skim and CombinedSkim steering files. So with this in mind, the way forward became clear. Lets create a way to side-step the path pickling and b2luigi standard steering script and instead use a custom steering script that is the user can point b2luigi to during run time. A similar idea had been done before here by Michael Eliachevitch. However, this had taken a more strict approach than I would like. Wherein the user could define their own jinja2 template which b2luigi would render, it would still pickle the basf2 path however. This idea was not merged into the main branch of b2luigi, instead remaining a feature branch. Taking inspiration from this idea the solution I created; the gbasf2_custom_steering_file attribute that can be set inside of a child class of Basf2PathTask, this attribute should be a path to a custom steering script on your local machine:
#-- Other imports above
from b2luigi.basf2_helper.tasks import Basf2PathTask
class docSkimSubmissionTask(Basf2PathTask):
#-- Defined luigi parameters above
gbasf2_custom_steering_file = 'path/to/local/custom/steering_file.py'
#-- The rest of your Basf2PathTask class including run, output and requires methods.
If gbasf2_custom_steering_file is set, b2luigi will skip path pickling and generating a steering script using its template. Instead, it checks that the path and file you have provided exists then uses this as the steering file to submit in the gbasf2 job. It is assumed the steering file creates and processes a basf2 path as the path pickling of the create_path method is skipped when using this feature. This feature was added to the main of b2luigi prior to version 1.0.0.
No pickling required, no writing initialiseSkimFlag as a C++ module, no template generated steering files and as a side affect it can allow conditional paths. Pretty neat! Because of its generic nature, gbasf2_custom_steering_file can be used with any steering script defined by the user, not just ones created using b2skim-generate.
The process of adding skims to VIBE#
How do we generate our skim steering script dynamically?#
Now that we can use custom steering files as discussed in the previous section, now comes the task of integrating b2luigi tasks into the VIBE workflow that will
Generate a custom steering file using b2skim-generate and skims defined by the user (still undecided how the user would define their required skims) and have it saved in the correct output folders
Submit gbasf2 jobs using the script generated in task 1.
This realised in the skim task folder vibe.core.tasks.skims with skim_template_task.py containing the b2luigi task that generates the skim steering file using b2skim-generate and skim_ntuple_production_task.py that submits a gbasf2 jobs using the generated script.
How does the task know what types of skims a given skim mode will be running? The most logical place to define this information would be in the skim mode itself. This is now where the dataclass SkimAttributes becomes important. We require that the author of the skim mode use the SkimAttributes class to define everything we need for the back-end of VIBE to generate the proper steering script. I think the most important part of SkimAttributes is that the user can overload the skim_name attribute, giving them the ability to run multiple skim types at once using a CombinedSkim. The beauty is that b2skim-generate automatically handles the switch case of single skims vs combined skims and so this was an extremely easy yet powerful addition to be added to VIBE.
How do we stop VIBE from downloading the skimmed ntuples?#
If we reference back to our workflow, you’ll note that when running online, we explicitly don’t download the ntuples. This is easy enough to toggle inside of the SkimProductionNtupleProductionTask inside of vibe.core.skims.skim_ntuple_production_task, we simply set gbasf2_download_dataset = False. Great, now our b2luigi won’t download our ntuples are we are happy…except now b2luigi has no way of verifying that a local output file has been created. Without this verification it has no way of knowing if a given task is complete or needs to be ran. This is obviously bad since one of the best parts about using b2luigi to orchestrate this skim-validation workflow was that we can change a parameter, say add another skim or add another dataset we would like to validate using our mode and b2luigi will orchestrate the workflow to only produce the jobs where our changed parameters matters.
All of this to say, SkimProductionNtupleProductionTask needs an output function that can check if our project is still running on the grid or if all jobs have been completed. It seems someone had thought of this already (yay) and b2luigi has a built in way to verify files on the grid.
# -- Other imports above
from b2luigi.batch.processes import gbasf2 as gb2
from b2luigi.basf2_helper.tasks import Basf2PathTask
class SkimProductionNTupleProductionTask():
gbasf2_download_dataset = False
# -- Defining SkimProductionNtupleProductionTask
def output(self):
if self.batch_system == 'gbasf2':
return gb2.Gbasf2GridProjectTarget(gb2.get_unique_project_name(self))
The gb2.Gbasf2GridProjectTarget in conjunction with gb2.get_unique_project_name allows us to verify if our project is still actively being written to on the grid or if the project is complete. With this, VIBE is comfortably able to check if a skim project is completed as it orchestrates VIBE
Without downloading the ntuples, how do we know the LPN’s to use in the validation section?#
What a great question, because on the surface it seems simple does it not? We submitted our job to the grid in SkimProductionNtupleProductionTask, we set the project name when we initialsied the skim object like so:
yield SkimProductionNTupleProductionTask(
base_path=self.base_path,
mode_name=mode.mode_name,
release=skim_release,
gbasf2_project_name_prefix=f"VSKIM_{mode.mode_name[:13]}_v4",
)
So simple we just find the project with the name corresponding to what I showed above. This simple question of ‘What is the LPN of our project?’ actually has a lot to unpack:
Did VIBE submit jobs under a group proxy such as data_prod or did we it submit using our personal grid certificate? The answer to this determines that base of our LPN path and we can’t know until runtime what the user did
Each b2luigi job has a unique 10 digit hash at the end of the gbasf2_project_name_prefix like so: “VSKIM_{mode.mode_name[:13]}_v40123456789”, how do we know what the hash is? This needs its own section to unpack
Was it a singular skim or a combined skim? If combined then the LPN is split after the project name into subdirectories index by the unique skim code given to every skim inside the skim Registry. If its a single then no extra subdirectories are made.
How do we dynamically add what the LPN’s will be to the skim mode JSON file during runtime so that the validation section of the workflow will not crash? What if the user needs to define dataset specific variables to pass into the create_basf2_path method during runtime?
So, what started as an easy question has ballooned into a daunting task. How do we put all these pieces together to seamlessly connect the skimming and validation workflows into one singular workflow. Remember, my goal is always to have to do as little as possible. I want to submit python3 vibe/vibe_main.py one time and have VIBE/b2luigi orchestrate everything for me. This includes taking care of all the unknowns during run time so I am not required to do a single thing more.
So the information required to build the LPN is something like this:
{1. the project lpn base path}/{2. the unique project name including hash}/{3. subdirectories if combined else no subdirectories}/sub0*/
So lets tackle this one piece at a time and build out LPN together.
1. How to determine the base of our grid LPN#
To do this, we would need to create some functionality to interface with the dirac proxy to handle accessing the project LPN path that has be initialised at run time when the dirac proxy was created (if it wasn’t already running). Now, like me you may have considered the fact that b2luigi would likely have some tools to handle this. And like me one that day, you would be correct. The creators of b2luigi have created a whole suite of tools to interface with the dirac API. Specifically,
from b2luigi.batch.processes import gbasf2 as gb2
from b2luigi.core.settings import get_setting as get_luigi_setting
get_luigi_setting("gbasf2_proxy_group", default='belle')
get_luigi_setting("gbasf2_project_lpn_path")
gb2.get_dirac_user()
So what do these functions give us? Well the get_luigi_setting (as I name it) is a function that holds all the metadata or settings for the b2luigi grid submission workflow. It works in conjunction with the b2luigi.setting method to gather settings and return default values if no setting exists. The gb2.get_dirac_user returns the username of proxy that is activated.
Note
In vibe/vibe_main.py we use the b2luigi.setting to set both the gbasf2_project_lpn_path and gbasf2_proxy_group to match the data production groups information.
So to find the base of our grid LPN we can use these functions like so.
from b2luigi.batch.processes import gbasf2 as gb2
from b2luigi.core.settings import get_setting as get_luigi_setting
# -- other imports
def get_output_lpn_dir(group_name):
if group_name != "belle":
return get_luigi_setting("gbasf2_project_lpn_path")
else:
return f'/{group_name}/user/{gb2.get_dirac_user()}'
if __name__ == "__main__":
group_name = get_luigi_setting("gbasf2_proxy_group", default='belle')
output_lpn = get_output_lpn_dir(group_name = group_name)
This function handles first, finding the gbasf2_proxy_group and second determining the gbasf2_project_lpn_path based on the proxy group that is returned. This exact function is attached the SkimProductionNTupleProductionTask as a @staticmethod and is used during runtime to determine the base of the LPN.
And with that, we have checked off 1 from our list. We have created a way to dynamically find the base of our skim grid LPN. No matter if a group proxy or a personal proxy is active, VIBE will be able to determine the base bath accurately.
2. How to determine the unique project name#
As stated before to determine that, what we need to know here is the unique 10 digit hash that b2luigi attaches to the end of the project being submitted. Now, since b2luigi is attaching the unique hash to the end of the project name, you can imagine there is a specific function that is able to create the hash.
from b2luigi.batch.process.gbasf2 import get_unique_project_name
The function get_unique_project_name is exactly the function we are looking for. This function takes an instance of a Basf2PathTask with basf2_system=”gbasf2” and returns the unique project name, hash and all. How the hash is generated for a given task is by taking the unique name luigi (not b2luigi) gives to a task, for example:
Example
VIBEMainTask__remote_nas00_1__9717673544
How luigi creates this unique name for the task is complex and involves taking the luigi.Parameter objects that are significant=True for a given task and doing a series of transforms to get the final product. Its not necessary to know the details exactly, however I spent a night going down this rabbit hole so if anyone wishes to discuss this topic please get in touch :D.
Details aside, we can easily use get_unique_project_name inside our SkimProductionNTupleProductionTask’s to determine the unique project name on the grid. Great, that’s two parts down, we need only one more piece of the LPN puzzle to be able to determine the LPNs to pass to the analysis section of the workflow.
3. Single vs Combined skims#
Unfortunately, unlike the first two hurdles, b2luigi does not have a function that will solve this problem. A few things need to be understood here
The formatting of the LPN for a single skim and combined skim are different. Lets say for this example, we are using our personal grid proxy, putting together the first two parts of our LPN the single and combined skim LPNs would look like so:
Single: /belle/user/{username}/VIBE_{mode_name}_v4_{unique identifier}/sub0*/
Combined: /belle/user/{username}/VIBE_{mode_name}_v4_{unique_identifier}/{skim_mode_code}/udst/sub0*/
We will know at run time if a skim is to be single or combined via the SkimAttributes object the user defines in their skim mode. If there is more than one skim name passed, then it will be a combined skim.
Great, so we need some mechanism that can translate what skims the user defines inside SkimAttributes to the appropriate LPN format. In this translation, we need to identify that
The skims the user has defined inside SkimAttributes are valid and registered inside of basf2
Convert the skim name into the unique skim code
Wow, so we really are building up a list of things we have to consider when generating the last part of the LPN. However, this web can be untangled bit by bit. Since the SkimAttributes is where the user defines the skims, it would be appropriate to attach our LPN logic to that dataclass. Lets begin by looking at our SkimAttributes dataclass, where I’ve attached a property called skim_type
@dataclass
class SkimAttributes:
"""
Dataclass that handles all the configuration a user can have for the skim mode they wish to develop.
Parameters
----------
skim_name : str | List[str]
A string or list of strings corresponding to valid skim names (i.e registered skim names). Note that if multiple skim names are given they must be in list form. Also important to note that every skim name given will be ran over every release lpn listed for the specific skim mode in skim_production_mode.JSON
globaltag : Optional[str] DEFAULT=None
Globaltag that will be prefixed to the basf2 path and used for every skim name. If none is given then it defaults to the most up to date globaltag. As of 13/3/24 that is 'analysis_tools_light-2212-foldex'
grid_test_mode : Optional[bool] DEFAULT=False
This flag if set to true will reduce the number of events per grid job to 100 events. Note that for skim names with low retentions, there is a chance that no ntuple will be saved to the grid if the retention threshold is not met.
skim_to_analysis_pipeline :Optional[bool] DEFAULT=False
This flag determines if b2luigi will schedule just a skim pipeline [False] (i.e just submit and monitor a skim job) or a full analysis pipeline [True]. If the user only wishes to generate a skim that will be saved to the grid for their own purposes then this flag should be set to false.
NOTE
----
The user must return as valid SkimAttributes dataclass inside of the 'get_skim_attributes()' function that is present in the skim mode class template.
"""
skim_name: List[str]
globaltag: Optional[str] = None
grid_test_mode: Optional[bool] = False
skim_to_analysis_pipeline: Optional[Union[bool,AnalysisParameters]] = False
@property
def skim_type(self):
pass
For now it doesn’t do anything, but what we want is for this property to dynamically generate the correct